TL;DR: A 2026 machine-learning study in PLOS One used student mental-health survey features to test an interpretable FT-Transformer plus LSTM model, which reached 95% accuracy for low, medium, and high risk prediction in a public dataset.
Key Findings
- 95% accuracy: the full interpretable FT-Transformer plus LSTM model outperformed AdaBoost, SVM, logistic regression, Random Forest, LSTM, and FT-Transformer baselines.
- 96% recall: the model’s strongest operational number was recall, the ability to catch true risk cases rather than miss them.
- Core inputs: anxiety, depression, productivity, social support, sleep, stress, activity, age, employment, and gender were modeled together.
- Interpretability layer: a Cross-Attention Attribution Layer (CAAL) was added so feature attention and sequence-style patterns could be inspected.
- Main caveat: the work used a public Kaggle dataset, so the benchmark does not prove the system is ready for campus screening.
Source: Dan Jiang published the model comparison in PLOS One, using a public mental-health dataset and code release to benchmark student risk prediction.
Student mental-health prediction is a tempting use case for artificial intelligence because schools often need earlier warning signs. It is also a risky one, because a model that looks accurate in a dataset can still fail when used with real students, real services, and real consequences.
Jiang’s analysis puts both sides in view. The full system reached 95.0% accuracy, 93.0% precision, 96.0% recall, and a 95.0% F1-score.
The caution is just as important: the data came from a public Kaggle mental-health dataset, not from a live college clinic.
Researchers Modeled Student Risk From Survey-Like Mental Health Features
The prediction target was a mental-health risk category: Low, Medium, or High. The input features covered emotional, behavioral, and demographic information.
The emotional side included anxiety score and depression score. The behavioral side included productivity, social support, sleep, stress, and physical activity. The demographic side included age, employment status, and gender encoding.
- Emotional features: anxiety and depression scores were treated as primary distress indicators.
- Behavioral features: productivity, social support, sleep, stress, and activity were modeled as ways distress may show up in daily life.
- Demographic features: age, employment, and gender were included as background variables.
The model did not diagnose depression or anxiety. It classified risk labels inside the dataset.
Dataset classification is not the same as clinical assessment, but it can still show whether a modeling approach deserves more careful testing.
The Hybrid Model Beat Simpler Machine-Learning Baselines
The main comparison table showed a clear performance ladder. AdaBoost reached 68.0% accuracy, SVM reached 70.5%, logistic regression reached 77.9%, and Random Forest reached 79.2%.
Deep-learning models performed better. A standalone LSTM, a neural network architecture often used for sequence patterns, reached 84.0% accuracy. A standalone FT-Transformer, a transformer model adapted for tabular features, reached 86.9% accuracy.
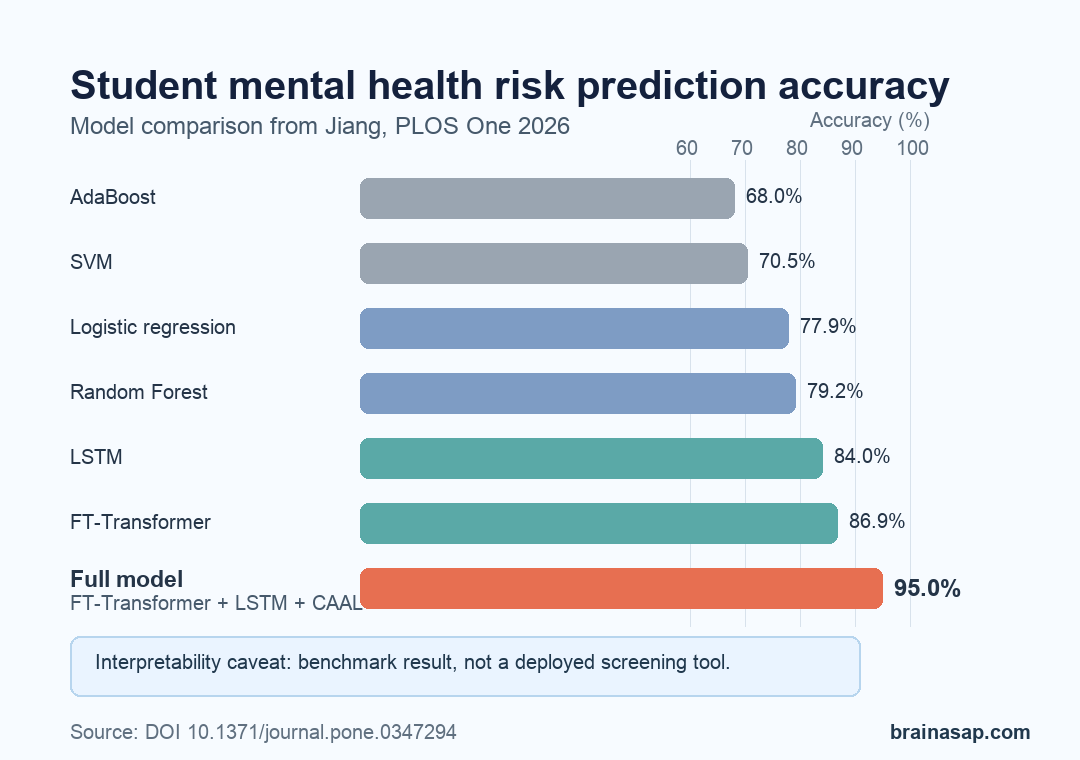
The full system combined those two model families and added CAAL, the paper’s interpretability bridge. That final version reached 95.0% accuracy, which was 8.1 percentage points higher than the standalone FT-Transformer and 11.0 points higher than the standalone LSTM.
Recall Is the Number to Watch in a Risk-Screening Context
Accuracy is easy to quote, but recall is often more important for risk screening. Recall asks how many true positive cases were actually detected.
In mental-health triage, a false negative can mean a student who needs support is missed.
The full model reported 96.0% recall. That was higher than the FT-Transformer baseline at 87.1%, the LSTM at 81.0%, and Random Forest at 80.3%.
- Precision: 93.0%, meaning most predicted risk cases were true positives inside the test setup.
- Recall: 96.0%, meaning the model missed fewer true risk cases than the baselines.
- F1-score: 95.0%, meaning precision and recall stayed balanced.
A model that improves accuracy while losing recall would be weaker for student support. In this benchmark, the full model improved both overall classification and high-sensitivity detection.
CAAL Was Built to Make the Model Less Opaque
The paper’s interpretability claim centers on the Cross-Attention Attribution Layer. CAAL connects feature attention from the transformer with sequence-style summaries from the LSTM.
In plain terms, the model is not only asking whether anxiety, depression, sleep, and stress are individually informative. It is also asking whether combinations such as depression with productivity decline or stress with reduced sleep help explain the predicted risk category.
- FT-Transformer role: learns cross-feature relationships in tabular mental-health data.
- LSTM role: treats the ordered feature set as a sequence-like emotional and behavioral pattern.
- CAAL role: maps how feature attention and temporal summaries interact before classification.
- LIME role: provides local explanations for individual predictions.
The paper also tested the model with statistical comparisons. Anxiety score, depression score, productivity score, social support, sleep, stress, and physical activity all showed statistically significant discriminative value in the feature table.
The Result Needs Real-World Validation Before Screening Use
The strongest caveat is external validity. A public Kaggle dataset can support model development, but it does not prove the same system would work in a university counseling center, a school health record, or a mobile check-in tool.
Future work named by the paper points in that direction: longitudinal behavioral data, academic performance data, ecological momentary assessments, journal text, activity logs, and wearable sensor data. Those sources would test whether the model can handle time-varying mental-health dynamics rather than one static benchmark.
Practical takeaway: the paper supports a careful research direction, not immediate automated triage. Interpretable models may help schools identify risk patterns earlier, but the next step is prospective validation with consent, privacy protections, equity checks, and a human support pathway.
Citation: DOI: 10.1371/journal.pone.0347294. Jiang D. Predicting student mental health through entropy-based features and interpretable cross-attention transformer networks. PLOS One. 2026;21(4):e0347294.
Study Design: Machine-learning model development and benchmark comparison using a public student mental-health dataset.
Sample/Model: FT-Transformer plus LSTM with a Cross-Attention Attribution Layer, compared with AdaBoost, SVM, logistic regression, Random Forest, LSTM, and FT-Transformer baselines.
Key Statistic: The full interpretable model reported 95.0% accuracy, 93.0% precision, 96.0% recall, and a 95.0% F1-score.
Caveat: The benchmark used a public dataset and needs prospective validation before use as a real student mental-health screening system.