
TL;DR: A 2026 medRxiv preprint found that plasma p-tau217 AI models still separated amyloid-positive from amyloid-negative people across ADNI and A4, but calibration drift made the same probabilities less dependable for clinical decisions.
Key Findings
- Calibration drift weakened clinical utility: The study trained plasma biomarker machine-learning models in one Alzheimer’s cohort and tested them in another without recalibration.
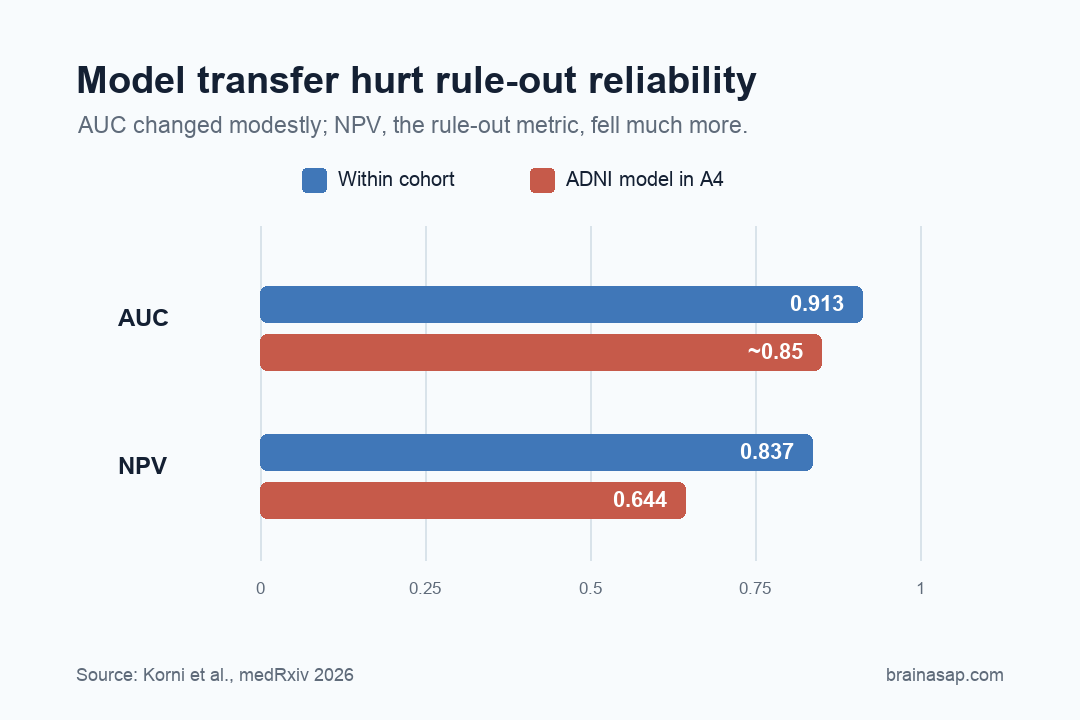
- AUC stayed fairly strong: Within-cohort amyloid positron emission tomography (PET) classification reached 0.913 in ADNI and 0.870 in A4, while cross-cohort transfer reduced discrimination by roughly 4-7%.
- Clinical utility degraded more: Negative predictive value fell from 0.837 inside ADNI to 0.644 when ADNI-trained models were deployed in A4.
- Calibration was the weak point: Predicted probabilities drifted away from observed amyloid positivity rates, especially in low-to-intermediate risk ranges.
- Assay and cohort shift mattered: Biomarker distributions differed between ADNI and A4 even after standard preprocessing, helping explain why portable accuracy did not guarantee portable decisions.
Source: medRxiv (2026) | Korni et al.
Plasma p-tau217 has become one of Alzheimer’s research’s most exciting blood biomarkers because it can track amyloid and tau pathology without a positron emission tomography scanner or spinal tap. But a biomarker model that works inside one research cohort can still stumble when it walks into another one.
This study tested the gap between ranking accuracy inside a dataset and calibrated clinical reliability in a new cohort.
Blood p-tau217 Was Not the Weak Link in the AI Models
Alzheimer’s blood tests have moved fast. Several inputs can help estimate whether amyloid is building up in the brain:
- Plasma p-tau217: a blood biomarker tied to Alzheimer’s tau and amyloid biology.
- Amyloid ratios: blood-based measures that approximate amyloid pathway changes.
- APOE genotype: inherited risk information that can improve prediction but does not decide diagnosis by itself.
- Clinical covariates: age and other patient features that can shift the model’s predicted probability.
Together, those markers are attractive for screening, trial recruitment, and routine care.
The trouble is that screening is not just about whether a model ranks people correctly. A clinician needs to know whether a specific predicted probability means the same thing in a new clinic, assay platform, or population.
A model can have a good receiver-operating curve and still be badly calibrated.
Why ADNI and A4 Made a Hard Test
The researchers used two major Alzheimer’s cohorts with different clinical shapes. ADNI includes a broader Alzheimer’s spectrum, while A4 is built around cognitively normal older adults being evaluated for preclinical amyloid risk.
ADNI and A4 make portability hard in different ways. A blood model trained in a mixed clinical cohort does not necessarily behave the same way in a mostly asymptomatic screening population.
Disease prevalence changes, biomarker distributions shift, and assay platforms do not always line up perfectly.
The transfer test had three parts:
- ADNI sample: 885 people with plasma biomarkers, covariates, and amyloid PET status.
- A4 sample: 724 people with the same broad data types but a different screening profile.
- Bidirectional transfer: models were trained within each cohort, then moved ADNI to A4 and A4 to ADNI.
The bidirectional setup tested portability rather than post-hoc optimization. It did not ask whether a model could look good after being tuned to the new dataset.
It asked what happens when a model leaves its training cohort without adjustment, which is closer to the first version of real-world deployment.
The Headline Accuracy Looked Reassuring
Inside each cohort, the models performed well. In ADNI, the best model reached an amyloid PET classification AUC of 0.913.
In A4, the best model reached AUC of 0.870. Those are strong discrimination numbers.
When the models crossed cohorts, the decline in AUC was real but not catastrophic. ADNI-trained models applied to A4 fell by about 4-7%.
A4-trained models applied to ADNI stayed in the roughly 0.83-0.87 range. If AUC were the only metric, the result would sound comforting.
But AUC answers a limited question: can the model rank amyloid-positive people above amyloid-negative people? It does not answer whether a predicted 20%, 40%, or 70% risk means what it says in the new population.
This is why biomarker AI can look better in papers than in clinics. Ranking performance helps research.
Clinical decisions need probabilities that remain meaningful when the patient mix changes.
The Rule-Out Number Broke More Than the Pretty Number
The more clinically relevant metric was negative predictive value: how confidently a model can rule out amyloid positivity. That is crucial if blood tests are used to decide who does not need expensive PET imaging or other follow-up.
Here, the cross-cohort result was much less reassuring. In ADNI, within-cohort negative predictive value was 0.837.
But when an ADNI-trained model was applied to A4, negative predictive value dropped to 0.644. That is not a tiny technical wobble. It changes how safe the model feels as a rule-out tool.
The reverse direction behaved differently because prevalence and sensitivity interact. A4-to-ADNI transfer produced high negative predictive value in some settings.
The study authors cautioned that this should not be read as better calibration or better generalization. It partly reflects the target cohort’s disease mix.
Calibration Is Where Translation Gets Real
Calibration decides whether a prediction can be trusted. If a model says 30 out of 100 people are likely amyloid-positive, then about 30 out of 100 similar people should actually be amyloid-positive.
If that relationship breaks, probabilities become misleading.
Cross-cohort calibration curves drifted away from the ideal line. ADNI-trained models applied to A4 showed systematic miscalibration, especially in the low-to-intermediate probability range.
That low-to-intermediate range is where many screening decisions happen.
The likely culprit was not that p-tau217 stopped being biologically meaningful. Feature importance stayed broadly consistent, with p-tau217 remaining a dominant predictor.
The problem was portability: the mapping between biomarker values, assay platforms, cohort composition, and amyloid PET status shifted.
This distinction points to three fixes before clinical deployment:
- Local recalibration: predicted probabilities should be checked against the clinic or cohort where the model will be used.
- Assay harmonization: blood-marker values need alignment across platforms rather than assuming every laboratory scale is interchangeable.
- Population validation: preclinical screening groups should be tested separately from symptomatic memory-clinic cohorts.
Recalibration should be treated as part of the medical device, not as an optional cleanup step after publication.
ADNI-to-A4 Drift Is the Problem Clinics Will Face
Blood-based Alzheimer’s screening will probably become part of clinical care. The question is how it enters.
If clinics treat model performance from one cohort as universal, they risk turning a strong biomarker into an overconfident decision aid.
The study argues for a stricter standard: external cohort validation, explicit calibration testing, and assay harmonization before deployment.
That standard prevents a model from silently changing meaning when moved from a research dataset to a real clinical workflow.
That standard should also be reported in language clinicians can use. A model’s AUC is not enough.
Papers need to show what happens to rule-out performance, false reassurance, and predicted risk across the exact populations where the test is plausibly used.
- Good discrimination is not enough: AUC can stay high while rule-out performance and predicted probabilities degrade.
- Prevalence changes the decision: A model built in a symptomatic cohort does not necessarily carry the same negative predictive value into a preclinical screening cohort.
- Assays need alignment: Platform differences can shift biomarker distributions even when the biology is real.
Alzheimer’s Blood-Test AI Needs Recalibration Before Deployment
This result is not a takedown of plasma p-tau217. It is almost the opposite.
Plasma p-tau217 stayed predictive enough that models still ranked risk reasonably well across cohorts. The failure was subtler: the numbers became less clinically dependable when the setting changed.
Alzheimer’s AI will need to solve this portability problem. The best models will not just score well inside famous datasets.
They will stay calibrated when assays, clinics, ancestry groups, disease stage, and prevalence shift around them.
Blood tests can make Alzheimer’s detection cheaper and earlier. If they are going to guide real decisions, they need more than impressive internal validation.
They need to survive the messy geography of actual medicine.
Citation: DOI: 10.64898/2026.04.09.26350514. Korni et al. Cross-Cohort Generalizability of Plasma Biomarker Machine Learning Models Reveals Calibration-Driven Degradation in Clinical Utility. medRxiv. 2026.
Study Design: Cross-cohort machine-learning validation preprint using plasma biomarkers and amyloid PET status.
Sample Size: 1,609 people across ADNI and A4, with models trained in one Alzheimer’s cohort and tested in another without recalibration.
Key Statistic: AUC stayed fairly strong: Within-cohort amyloid PET classification reached 0.913 in ADNI and 0.870 in A4, while cross-cohort transfer reduced discrimination by roughly 4-7%.
Caveat: Preprint evidence from research cohorts; real-world clinics may add further assay, ancestry, prevalence, and workflow shifts.





