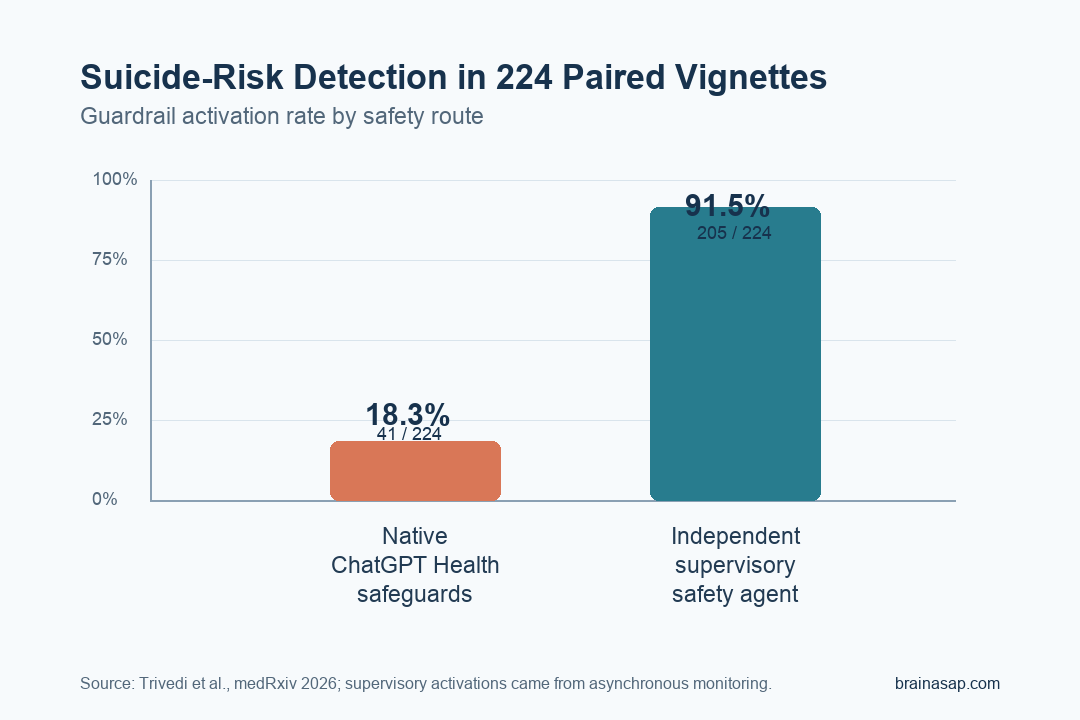
TL;DR: A 2026 preprint on medRxiv tested suicide-risk vignettes and found that an independent supervisory safety agent detected intervention-level risk far more often than native ChatGPT Health safeguards.
Key Findings
- 224 paired evaluations: Researchers tested suicide-related clinical vignettes under two information conditions, creating 224 paired comparisons between native safeguards and an external supervisory system.
- 91.5% versus 18.3% detection: The supervisory safety architecture detected suicide risk in 205 of 224 evaluations, compared with 41 of 224 for native ChatGPT Health safeguards.
- 166 discordant cases favored supervision: Among 168 mismatched evaluations, 166 were detected only by the supervisory architecture and 2 only by ChatGPT Health.
- Asynchronous monitoring did the work: Every supervisory-system activation came from the external monitoring pathway rather than from a synchronous real-time guardrail.
- Ambiguous cases stayed harder: Detection was strongest for explicit suicidal ideation and lower when the vignette contained indirect or alcohol-associated risk cues.
Source: medRxiv preprint (2026) | Trivedi et al.
Language models are already being used around mental-health questions, which makes suicide-risk detection a practical safety problem rather than a theoretical benchmark issue. Researchers tested whether a safety layer outside the model could catch risk that the model’s own crisis safeguards missed.
The setup was a structured evaluation of suicide-related clinical vignettes, not a claim that the system is ready for live clinical deployment.
Supervisory Monitoring Detected More Suicide-Risk Vignettes
Researchers compared two safety routes across 224 paired evaluations. One route relied on native ChatGPT Health crisis-safeguard behavior.
The other used an independent supervisory safety architecture, meaning a separate monitoring system that evaluated risk outside the base model response.
The detection gap was large:
- Supervisory safety architecture: 205 of 224 evaluations triggered risk detection, or 91.5%.
- Native ChatGPT Health safeguards: 41 of 224 evaluations triggered risk detection, or 18.3%.
- Matched comparison: The reported matched odds ratio was about 83.0, reflecting how one-sided the discordant cases were.
The supervisory system still may not have understood every clinical nuance. In this test set, external monitoring caught many risk cues that native safeguards did not act on.
Most Mismatches Favored the External Safety Layer
The paired design matters because it shows where the systems disagreed on the same evaluation structure. Among 168 discordant evaluations, the supervisory architecture identified risk in 166 cases where native ChatGPT Health safeguards did not.
Only 2 discordant cases went the other direction. Another 39 evaluations were detected by both systems, while 17 evaluations were missed by both.
The mismatch points to a specific safety lesson. Model-internal safeguards may work for some obvious crisis presentations, but they can leave large gaps when risk is expressed in varied clinical language.
An outside monitor can act as a second review channel rather than depending on the model’s first response to notice the danger.
Asynchronous Monitoring Was the Active Safety Pathway
The supervisory system used asynchronous monitoring, which means the safety review was decoupled from the model’s immediate response generation. In this evaluation, all supervisory activations came from that monitoring pathway.
That is a useful distinction for AI safety design. A real-time guardrail may need to interrupt or shape the first answer.
An asynchronous monitor can separately evaluate the interaction and escalate risk if the model response itself fails to flag it.
The study frames this as a model-agnostic safety layer. In principle, the same oversight approach could be applied across different LLM systems without retraining each underlying model.
- Base model: Generates or responds in the normal application flow.
- Supervisory monitor: Reviews the user scenario or output for risk indicators.
- Escalation layer: Triggers the safety response when the monitor detects suicide-risk content requiring intervention.
For high-risk mental-health applications, that separation is the main point. The system does not have to trust the model’s own safety behavior as the only line of defense.
Explicit Ideation Was Easier Than Ambiguous Risk
Detection was not uniform across every vignette type. Scenarios involving explicit suicidal ideation, including passive ideation or method-related content, reached the strongest coverage.
More ambiguous presentations were harder. The paper specifically notes lower activation rates in scenarios with less direct indicators of risk, including alcohol-associated suicidal ideation.
That caveat is clinically important because real conversations often do not arrive as clean textbook crisis statements. People may describe sleep disruption, substance use, hopelessness, agitation, or self-harm risk indirectly.
The result supports two practical requirements for AI mental-health safety systems:
- Explicit-risk handling: Systems need reliable detection when suicidal ideation is directly stated.
- Ambiguity handling: Systems also need testing against indirect, mixed, and substance-associated presentations.
- Auditability: External monitoring can create a clearer record of what was detected, missed, or escalated.
Synthetic Vignettes Limit the Clinical Claim
The study is best read as a safety-architecture test, not as proof of clinical effectiveness. Researchers used structured synthetic vignettes in a single-turn format, which is simpler than real multi-turn conversations with changing risk over time.
The evaluation was also limited to suicide-related scenarios within one testing framework. It does not show how the architecture would perform across broader psychiatric presentations, different languages, live users, or noisy consumer-app settings.
Still, the direction of the finding is clinically relevant. If native safeguards detect fewer than one in five intervention-level risk evaluations in this structure, mental-health AI systems need safety layers that do not depend entirely on the base model’s first-pass judgment.
Practical takeaway: the paper supports a defense-in-depth approach. In high-risk mental-health contexts, a separate supervisory monitor may be safer than relying on native LLM safeguards alone, but it still needs real-world, multi-turn validation before it can be treated as a clinical safety solution.
Citation: DOI: 10.64898/2026.04.13.26350757. Trivedi et al. An independent supervisory safety agent improves reaction of large language models to suicidal ideation. medRxiv. 2026.
Study Design: Cross-sectional evaluation of suicide-related clinical vignettes using paired model-safety comparisons.
Sample Size: 224 paired evaluations from seven suicide-related scenario groups and two information conditions.
Key Statistic: Supervisory detection was 205 of 224 evaluations (91.5%) versus 41 of 224 (18.3%) for native ChatGPT Health safeguards.
Caveat: The work used synthetic single-turn vignettes and was a preprint, so it should not be treated as validated clinical deployment evidence.