TL;DR: A 2026 Scientific Reports study reported that machine learning models classified brain tumor MRI images across four categories with high internal accuracy, led by a convolutional neural network at 99.29% on a single public dataset.
Key Findings
- 7,023 MRI images: Researchers trained and tested models on 7,023 brain MRI images from a publicly available dataset.
- Four classes: The image labels covered glioma, meningioma, pituitary tumor, and no tumor.
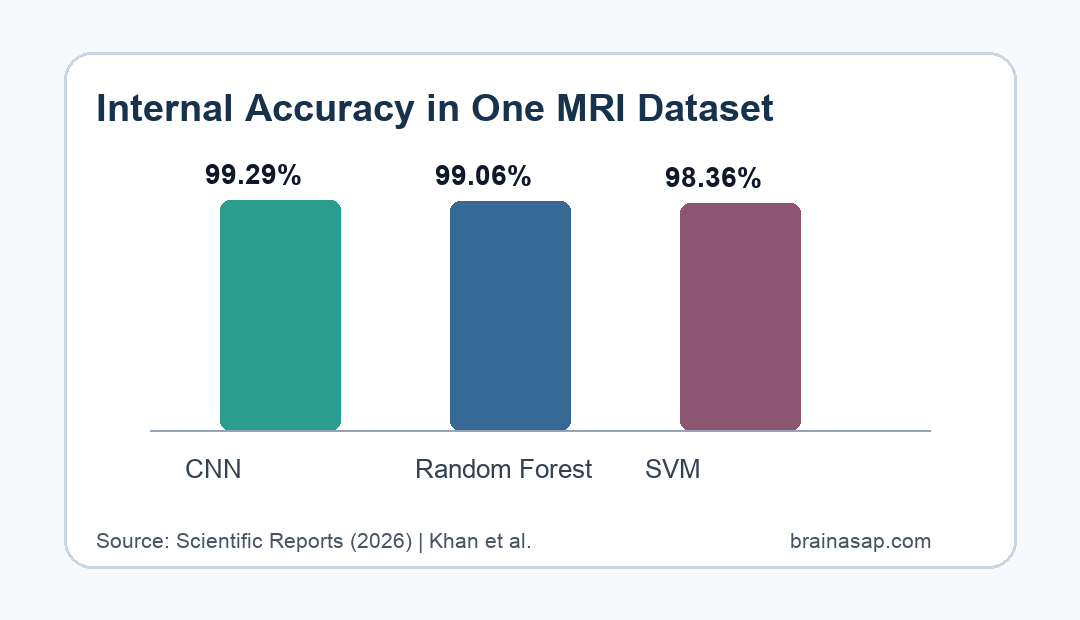
- 99.29% CNN accuracy: The convolutional neural network (CNN), a deep-learning image classifier, had the highest reported accuracy at 99.29%.
- 99.06% RF accuracy: Random forest (RF), a tree-based machine learning method, reached 99.06% accuracy using extracted image features.
- 98.36% SVM accuracy: Support vector machine (SVM), a boundary-based classifier, reached 98.36% accuracy, but the study lacked external validation.
Source: Scientific Reports (2026) | Khan et al.
Brain tumor MRI classification is a natural target for machine learning because radiologists often have to separate visually similar tumor types across large imaging sets. This study tested whether three model types could classify MRI images into tumor and non-tumor categories.
The strongest result is the internal performance number. All three classifiers exceeded 98% accuracy, but the evidence is still a dataset benchmark rather than proof that the system works in routine hospital imaging.
CNN, RF, and SVM Models Classified Four Brain MRI Categories
The dataset included 7,023 MRI images labeled as glioma, meningioma, pituitary tumor, or no tumor. Those categories represent a practical multiclass problem rather than a simple tumor-versus-normal screen.
Researchers compared three approaches. The CNN learned image features directly from MRI data, while RF and SVM relied on extracted features prepared before classification.
- CNN: A convolutional neural network learned spatial and textural image patterns from the MRI images.
- RF: Random forest combined many decision trees to classify feature patterns.
- SVM: Support vector machine separated image-feature groups using a learned boundary.
This setup is clinically relevant because brain tumor imaging has overlapping visual features. A glioma and another intracranial mass can look similar enough that model performance needs careful class-by-class testing, not only a single overall score.
The CNN Led With 99.29% Internal Accuracy
The CNN had the highest reported accuracy at 99.29%. RF followed closely at 99.06%, and SVM reached 98.36%.
Those differences are small in absolute terms, but the ranking is consistent with the model design. CNNs are built for image data, while RF and SVM generally depend more heavily on the quality of handcrafted features.
- Image-first learning: CNNs can learn edges, textures, and spatial combinations directly from MRI slices.
- Feature-engineered learning: RF and SVM can perform well when extracted features capture the relevant visual differences.
- Benchmark strength: Similar high scores across models suggest the dataset contains learnable visual structure.
Accuracy alone is not enough for clinical use. A model can score well overall while still making clinically important errors in a smaller tumor class, so confusion matrices and receiver operating characteristic analyses remain important.
The four-way classification also changes the interpretation of the headline accuracy. A binary tumor detector could perform well by learning a broad abnormal-versus-normal distinction, but this dataset required the models to separate three tumor types from no tumor.
The four-class setup makes the benchmark closer to a diagnostic-support task, although it still falls short of real patient triage.
Hospital scans include variable image quality, prior surgery, edema, treatment effects, unusual tumor locations, and lesions that are not represented in a curated public dataset.
Single-Dataset Testing Limits Clinical Interpretation
The main limitation is clear: the study used a single public dataset and did not report external validation on images from another hospital, scanner mix, or patient population.
That limitation is important for medical imaging AI. Models can learn dataset-specific clues, preprocessing patterns, scanner artifacts, or label distributions that do not hold up in a new clinic.
- External validation: A stronger next test would use MRI scans from independent centers.
- Prospective workflow: Clinical usefulness would require testing how the model performs in real diagnostic workflows.
- Class-specific errors: A practical tool must show where false positives and false negatives occur for glioma, meningioma, pituitary tumor, and no tumor.
The study therefore supports model feasibility, not autonomous diagnosis. Any clinical pathway would still need radiologist review, tumor board context, pathology when indicated, and regulatory-quality validation.
A second limitation is prognosis. The title includes diagnosis and prognosis, but the core evidence described in the abstract is image classification across tumor categories.
Prognosis would require outcome-linked follow-up, such as survival, progression, recurrence, treatment response, or postoperative functional status.
That does not make the classification work useless. It means the model should be read first as a tumor-type classifier, with prognosis left as a future clinical-integration goal rather than a demonstrated patient-outcome result.
MRI AI Could Support Brain Tumor Triage If It Generalizes
If the results generalize, MRI classifiers could help prioritize suspicious scans, support subtype classification, and reduce variability in first-pass reads. The most useful role would likely be decision support rather than replacement of specialist interpretation.
The paper also points toward future directions such as federated learning and multicenter datasets. Federated learning would allow models to learn from multiple institutions without pooling raw patient images in one location.
- Clinical support: AI could flag likely tumor class before specialist review.
- Data diversity: Multicenter training would make performance less dependent on one dataset.
- Safety check: Any deployment would need monitoring for errors across age groups, scanners, tumor classes, and image quality levels.
The validation question is specific. A 99% benchmark supports further testing, but the next question is whether the same classifier holds up when MRI images are messier, more diverse, and tied to real clinical consequences.
Citation: DOI: 10.1038/s41598-026-50213-x. Khan et al. Neuroimaging and machine learning fusion for improved brain tumor diagnosis and prognosis. Scientific Reports. 2026.
Study Design: Machine learning benchmark study using labeled brain MRI images.
Sample Size: 7,023 MRI images across glioma, meningioma, pituitary tumor, and no-tumor categories.
Key Statistic: CNN accuracy was 99.29%, compared with 99.06% for RF and 98.36% for SVM.
Caveat: The models were tested on a single public dataset without external clinical validation.