TL;DR: A 2026 study in Journal of Affective Disorders used interpretable machine learning to predict who completed more prompts during a 14-day mindfulness app trial for generalized anxiety disorder.
Key Findings
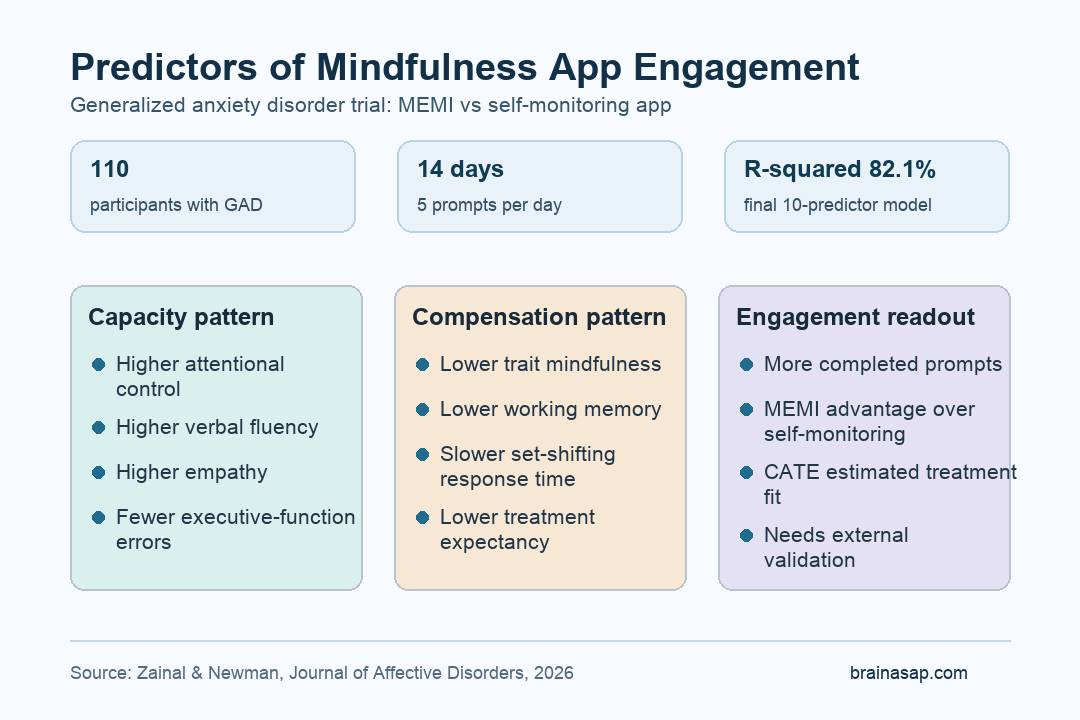
- Trial size: A two-arm randomized trial included 110 people with generalized anxiety disorder, assigned to a mindfulness ecological momentary intervention or a self-monitoring app.
- Full model: The 16-variable machine-learning model predicted two-week prompt completion with R2 = 82.7%.
- Smaller model: A tighter 10-predictor model kept similar accuracy, with R2 = 82.1% and lower prediction error.
- Mindfulness advantage: Predicted engagement was higher for the mindfulness app than self-monitoring, with a d = 1.447 differential engagement estimate.
- Top predictors: The strongest predictors included working memory, trait mindfulness, attentional control, anxiety severity, set-shifting speed, verbal fluency, empathy, expectancy, inhibition speed, and executive-function errors.
Source: Zainal and Newman. Journal of Affective Disorders. 2026.
Machine Learning Predicted Mindfulness App Engagement in Generalized Anxiety Disorder
Digital mental health tools often fail for a practical reason: people stop using them. Low engagement can make a promising phone-based program look weak even when the underlying treatment idea is reasonable.
The intervention was a mindfulness ecological momentary intervention (MEMI), meaning a phone-based program that delivered short mindfulness prompts during everyday life. The comparison arm used self-monitoring (SM), an app that asked people to observe anxiety and mood without teaching mindfulness skills.
The engagement outcome was concrete. Researchers counted the number of app prompts each participant completed across 14 days, then log-transformed that count for the prediction models.
Both arms received 5 daily prompts, scheduled at 9 in the morning, noon, 3:00, 6:00, and 9:00 p.m.
The MEMI prompts coached diaphragmatic breathing, present-minded attention, acceptance, and non-judgmental observation. The SM prompts tracked distress without those mindfulness instructions.
The Trial Compared Mindfulness Prompts With Self-Monitoring Prompts
The study used data from a randomized controlled trial with 110 participants diagnosed with GAD. Researchers assigned 68 participants to MEMI and 42 participants to SM.
The baseline predictor set was intentionally broad. Researchers included clinical symptoms, demographic variables, treatment-process measures, and executive-function tests because app engagement may depend on both distress level and the ability to use a skill repeatedly.
- Clinical measures: Depression symptoms, GAD severity, and repetitive negative thinking.
- Process measures: Trait mindfulness, treatment credibility, treatment expectancy, and empathy.
- Executive-function measures: Attentional control, inhibition response time, set-shifting response time, verbal fluency, working memory, and executive-function errors.
- Demographic measures: Age, sex, and race were also entered in the full model.
The machine-learning workflow used random forest models with five-fold nested cross-validation. Nested cross-validation is a stricter model-testing setup because it separates model tuning from model evaluation, reducing the chance that performance is inflated by overfitting.
The 10-Predictor Model Kept More Than 80% Predictive Accuracy
The full 16-predictor model performed strongly, with R2 = 82.7%, root mean squared error (RMSE) of 0.780, and mean absolute error (MAE) of 0.512. R2 describes how much variance in the engagement outcome the model explained.
Researchers then used SHAP, short for Shapley additive explanations, to identify which variables contributed most to the model’s predictions. SHAP is an interpretability method that estimates how much each feature pushes a model prediction up or down.
The final 10-predictor model kept nearly the same R2, at 82.1%, while lowering prediction error. Its RMSE was 0.547 and its MAE was 0.307.
The smaller model was easier to interpret without giving up much predictive power.
The top variables were not just demographic descriptors. They were mostly cognition, anxiety, mindfulness, empathy, and expectancy measures that could plausibly affect whether someone follows through with a repeated app-based practice.
Working Memory and Mindfulness Were the Highest-Ranked Predictors
The top-ranked predictors were based on absolute SHAP values, so the rank describes model importance rather than a simple correlation. Working memory and trait mindfulness had the highest ranks, followed closely by attentional control and GAD severity.
The ranked list shows why a single engagement explanation is too simple. Some predictors were capacity factors, such as attention and verbal fluency.
Others were need or fit factors, such as lower baseline mindfulness or lower treatment expectancy.
- Working memory: Lower working memory predicted more relative engagement with MEMI than SM.
- Trait mindfulness: Lower baseline mindfulness also predicted more relative engagement with MEMI.
- Attentional control: Higher attentional control predicted more relative engagement with MEMI.
- GAD severity: Lower GAD severity predicted more relative engagement with MEMI.
- Set-shifting response time: Slower set-shifting response time predicted more relative engagement with MEMI.
- Verbal fluency and empathy: Higher scores predicted more relative engagement with MEMI.
The study used conditional average treatment engagement (CATE) to estimate which baseline profiles predicted more engagement with MEMI compared with SM. Higher CATE values meant a larger predicted engagement advantage for the mindfulness app.
Overall, the CATE analysis estimated higher engagement when participants received MEMI rather than SM, with d = 1.447 and p < .001.
The model found a strong engagement difference inside this sample, but the finding is not a ready-to-use automatic assignment rule.
The Predictor Pattern Mixed Capacity and Compensation
The researchers interpreted the pattern through 2 ideas. A capitalization model suggests people engage more when a treatment fits their strengths.
A compensation model suggests people engage more when a treatment gives structure around a weakness.
Several findings fit the capacity side. Higher attentional control, higher verbal fluency, higher empathy, lower inhibition response time, and fewer executive-function errors were linked with more predicted MEMI engagement than SM engagement.
Other findings fit the compensation side. Lower working memory, slower set-shifting, lower trait mindfulness, and lower treatment expectancy also predicted more relative MEMI engagement.
In plain terms, the app may have engaged some people because it gave repeated structure for skills they had not already built.
- Skill-learning demand: MEMI required people to practice breathing, present-minded attention, and non-judgmental observation.
- Repeated structure: Five prompts per day may have supported people who had trouble holding or transferring the practice on their own.
- Newness of the skill: Lower baseline mindfulness may have left more room for the prompts to seem relevant and worth repeating.
- Initial skepticism: Lower treatment expectancy may have shifted once participants experienced the brief exercises.
The Main Limit Is Validation Beyond This Small Sample
The strongest caveat is sample size. The trial included 110 participants, and the model tested engagement over only 2 weeks.
The sample was also mostly young and predominantly White, so the predictor pattern needs replication in larger and more diverse clinical groups.
The engagement metric was narrow. Prompt completion is informative, but it does not capture whether participants practiced carefully, understood the instructions, or benefited clinically from the app.
The study points to a more specific digital mental health question. Instead of asking whether people use mindfulness apps in general, it asks which baseline profiles predict engagement with a skill-building mindfulness app compared with a tracking-only app.
Practical takeaway: brief digital mindfulness programs may need different support layers for different users.
Some people may engage because they already have enough attentional control to use the prompts well. Others may engage because the prompts supply a structure they lack.
Citation: DOI: 10.1016/j.jad.2025.120963. Zainal and Newman. Who engages? Machine learning insights into digital mindfulness-based intervention for generalized anxiety disorder. Journal of Affective Disorders. 2026;399:120963.
Study Design: Secondary machine-learning analysis of a two-arm randomized controlled trial comparing mindfulness ecological momentary intervention with a self-monitoring app.
Sample Size: 110 people with generalized anxiety disorder, including 68 assigned to MEMI and 42 assigned to self-monitoring.
Key Statistic: The final 10-predictor random forest model explained 82.1% of variance in two-week prompt completion, with RMSE 0.547 and MAE 0.307.
Caveat: The model used a small, mostly young sample, a single engagement metric, and a two-week follow-up, so the predictor pattern needs external validation.