TL;DR: A 2026 medRxiv review found that mental-health AI agents are moving quickly toward large-language-model chatbots, but most systems still rely on text self-report, narrow depression/anxiety/suicide use cases, and offline tests rather than prospective clinician or patient trials.
Key Findings
- More than 300 recent papers were reviewed: Researchers audited mental-health AI agent systems from 2023 to 2025 across model type, data source, clinical focus, demographics, task, and evaluation method.
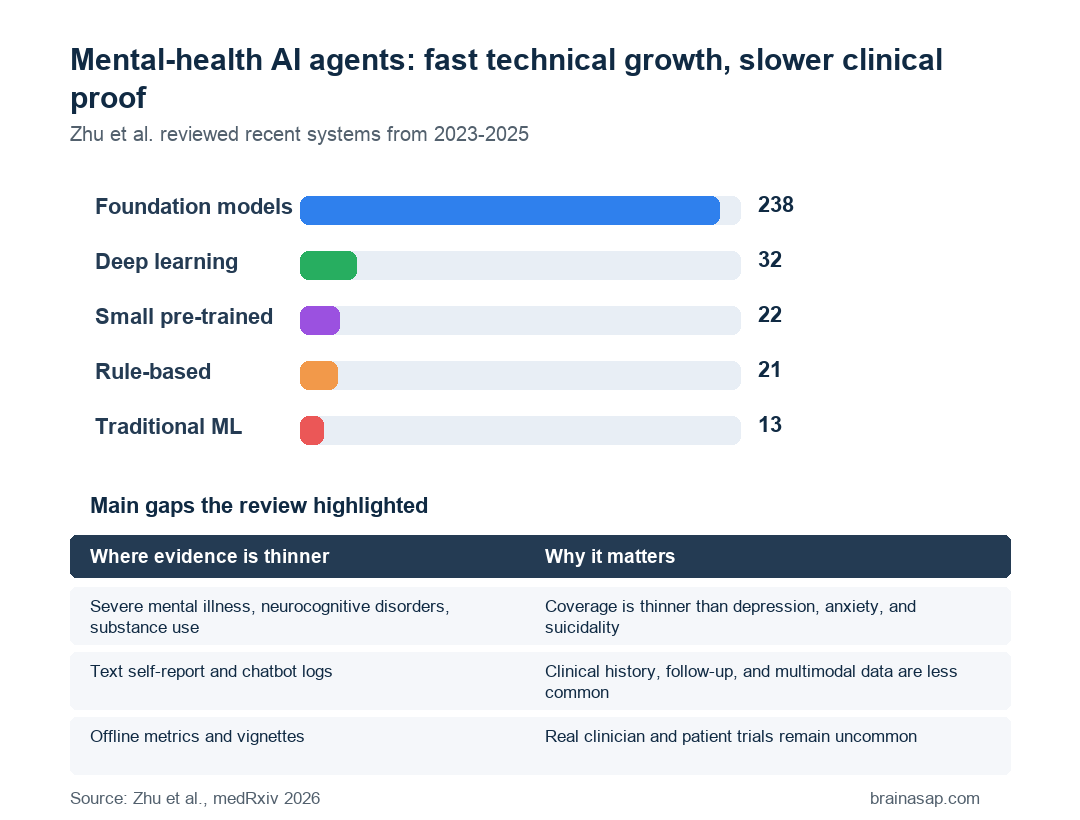
- Foundation models dominated the newer corpus: Among post-2023 systems, 238 used foundation models, compared with smaller counts for rule-based, traditional machine-learning, deep-learning, and small pre-trained models.
- Clinical coverage was uneven: Depression, anxiety, and suicidality received much more attention than severe mental illness, neurocognitive disorders, substance use, and complex comorbidity.
- Most systems used text-heavy self-report: The review found less use of clinically verified longitudinal data, electronic health records, biosensing, or genuinely multimodal mental-health streams.
- Evaluation remained the weak point: Many systems were tested with offline metrics or vignettes, while prospective clinician- or patient-in-the-loop studies remained uncommon.
Source: medRxiv preprint (2026) | Zhu et al.
Mental-Health AI Agents Are Not All the Same Tool
AI agents in this review meant systems that do more than return one chatbot answer. Some planned steps, retrieved outside information, used tools, coordinated specialized sub-agents, or handled structured clinical workflows such as triage, documentation, risk assessment, or decision support.
This definition prevents mental-health AI from collapsing into one therapy-chatbot category. Researchers separated the field into a broader technical map, including rule-based tools, traditional machine-learning classifiers, deep-learning systems, small pre-trained models, and newer foundation-model agents.
The shift was clear. In the recent corpus, 238 systems used foundation models. The review still counted smaller groups of rule-based, traditional machine-learning, deep-learning, and small pre-trained systems.
The center of gravity has moved toward general-purpose models adapted for mental-health tasks.
Depression, Anxiety, and Suicide Risk Got Most Attention
The clinical map was not evenly distributed. Systems clustered around problems that are common, text-expressible, and easier to study with online or questionnaire data.
- Common targets: Depression, anxiety, psychological distress, suicidality, stress, and general emotional support appeared frequently.
- Thinner areas: Severe mental illness, neurocognitive disorders, substance use, multimorbidity, and complex diagnostic overlap received less coverage.
- Task mix: The systems handled screening, triage, clinical decision support, therapy-adjacent conversation, documentation, education, simulation, and AI safety assessment.
This imbalance is understandable, but it creates a clinical blind spot. The disorders most likely to require specialist care, longitudinal context, collateral information, and safety escalation are not necessarily the ones best represented in current agent research.
Text Self-Report Still Drives Much of the Evidence
The review emphasized a second gap: data source. Many mental-health agents were built around elicited self-report, chatbot dialogue, questionnaires, or synthetic prompts.
Those sources are useful, but they do not equal a verified clinical history.
Richer systems are starting to combine text with electronic health records, speech, biosensing, behavioral traces, lab data, or multimodal streams. Mental-health risk often depends on repeated symptoms, treatment history, functional change, and clinician-confirmed outcomes.
- Clinical verification: A symptom label from a prompt is weaker than diagnosis, outcome, medication, hospitalization, or clinician-confirmed follow-up.
- Longitudinal context: Risk assessment changes when a system can distinguish a transient mood statement from a repeated deterioration pattern.
- Privacy cost: Multimodal and longitudinal data can improve context, but they also raise higher stakes for consent, storage, bias, and regulatory accountability.
The practical problem is not that text data are useless. It is that text-only systems can look clinically fluent while operating with a narrow view of the person, the diagnosis, and the risk environment.
Evaluation Has Not Kept Up With Capability
The most important warning in the review is about testing. A mental-health system can perform well on an automated benchmark, vignette, expert-written scenario, or language-quality score and still fail when a distressed person uses it repeatedly in daily life.
The review described evaluation types ranging from automated metrics to safety stress tests, expert review, usability testing, and clinician or patient involvement. The field has many examples of early-stage evaluation, but fewer prospective studies where real users, clinicians, outcomes, and harms are followed over time.
- Offline metrics: Useful for comparing systems, but weak evidence for clinical safety.
- Vignettes and simulations: Better for controlled stress testing, but still limited by artificial scenarios.
- Clinician and patient studies: More relevant to real deployment, but harder, slower, and less common.
This distinction is central. Mental-health AI can sound safe in a static answer while failing at escalation, boundary-setting, over-reassurance, crisis handoff, or dependence risk across repeated interactions.
Multi-Agent Workflows Could Help, But They Add New Risks
The review did not treat agentic architecture as automatically better. More moving parts can improve specialization, but they also create more places for failure.
Emerging systems assign different roles to planners, retrieval agents, safety auditors, supervisors, diagnostic helpers, or tool-using components. In principle, that architecture can separate emotional support from risk screening, evidence retrieval, and clinical documentation.
- Potential benefit: A safety auditor can check whether a conversational agent missed escalation cues or gave unsupported advice.
- Potential failure: A planner, retrieval tool, and chatbot can amplify each other’s mistakes if no reliable clinical guardrail interrupts the workflow.
- Deployment burden: More agent roles mean clearer accountability is needed when advice, triage, or documentation affects care.
The practical takeaway is straightforward: mental-health AI should be judged less by whether it uses a large model and more by what data it sees, what task it is allowed to perform, how it handles risk, and whether humans tested it in the setting where it would actually be used.
The Review Is a Map, Not a Clinical Endorsement
This paper is a preprint review, so it should not be treated as a practice guideline. It organizes a fast-moving research field rather than proving that any one mental-health AI system is ready for unsupervised clinical use.
The strongest contribution is its framework. By separating system type, data scope, clinical focus, demographics, task, and evaluation method, the review gives readers a way to ask better questions before accepting a polished mental-health AI demo.
That framework also explains why the field can feel both promising and underproven. The technology is becoming more agentic, role-aware, and multimodal. The clinical evidence base is still catching up.
Citation: DOI: 10.64898/2026.04.21.26351365. Zhu et al. Artificial Intelligence Agents in Mental Health: A Systematic Review and Meta Analysis. medRxiv. 2026.
Study Design: Systematic review and meta-analysis-style technical audit of mental-health AI agent systems published or posted from 2023 to 2025.
Sample Size: More than 300 recent papers on mental-health AI agent systems, including 238 foundation-model systems in the post-2023 annotated corpus.
Key Statistic: Foundation-model systems were the largest model-lineage group, while prospective clinician- or patient-in-the-loop evaluations remained uncommon.
Caveat: The source is a preprint and should not be used as clinical guidance for mental-health AI deployment.