TL;DR: A 2026 systematic review in BMC Medical Informatics and Decision Making found that AI models using remote-monitoring data were most often studied in Parkinson’s disease, but 56 of 76 prospective studies had high risk of bias.
Key Findings
- 6,668 records were screened: Researchers narrowed the search to 76 prospective studies of machine learning for chronic-disease outcomes using remote monitoring.
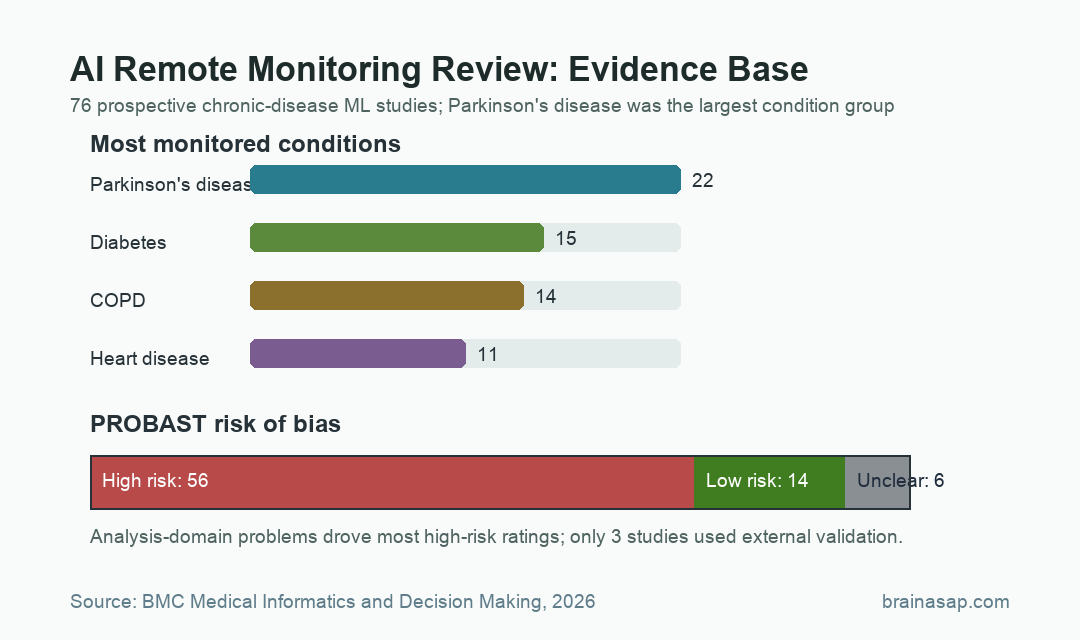
- Parkinson’s disease led the field: Parkinson’s disease appeared in 22 included studies, followed by diabetes in 15, COPD in 14, and heart disease in 11.
- Bias risk was high: PROBAST review classified 56 studies as high risk of bias, 14 as low risk, and 6 as unclear.
- Wearables dominated data collection: 53 studies used wearable devices, and raw accelerometer data was the most common input parameter.
- External validation was rare: Only 3 studies used external validation, while 64 used some form of cross-validation.
Source: BMC Medical Informatics and Decision Making (2026) | Wolber et al.
AI Remote Monitoring Was Most Common in Parkinson’s Disease
Remote patient monitoring is attractive because chronic diseases often change outside the clinic. Wearables, home sensors, questionnaires, and active measurement devices can capture movement, symptoms, heart rate, oxygen saturation, and sleep during ordinary life.
The 2026 review asked a narrower question: when researchers combine those remote data streams with machine learning, how strong is the evidence for predicting chronic-disease outcomes?
After screening 6,668 records, researchers included 76 prospective studies published from 2014 through 2024. Retrospective studies, simulated data, proprietary models without enough methodological detail, and hospital-only monitoring were excluded.
The condition mix was not evenly spread. Parkinson’s disease accounted for the largest group with 22 studies, which makes practical sense because wearable sensors can capture movement patterns, freezing of gait, tremor-related features, and medication-state changes.
Diabetes, COPD, and heart disease also had substantial representation. Chronic kidney and liver disease had no included studies, suggesting that some chronic conditions remain harder to measure remotely with noninvasive tools.
Wearables and Accelerometers Drove the Monitoring Data
The review found that 53 studies used wearable devices. These included smartwatches, implantable cardioverter defibrillators, glucose monitors, and other sensors that can collect repeated data outside a clinic.
Active measurement devices were also common. Twenty studies used tools such as pulse oximeters, weight scales, or blood pressure monitors, and 20 studies used patient questionnaires.
The most frequent input was raw accelerometer data, used in 33 studies. Heart rate appeared in 21 studies, and symptom data appeared in 11.
Those choices shaped what the field could study:
- Movement-heavy diseases: Parkinson’s disease is well matched to accelerometers because motor fluctuations can be measured repeatedly.
- Broad physiology data: Heart rate was used across eight different conditions, making it less condition-specific but more widely available.
- Patient-reported outcomes: Questionnaires can capture symptoms at home, but the review noted known limitations such as reporting bias and adherence burden.
The review also flagged a labeling problem. In one cited Parkinson’s study, prediction performance was 12% to 20% lower when patient-reported labels were used instead of expert labels.
That finding does not make patient reports useless. It shows that AI models trained on remote data depend heavily on how the “correct answer” is defined.
56 of 76 AI Remote Monitoring Studies Had High Bias Risk
The most important result was not that machine learning worked or failed. It was that the research base had major methodological weaknesses.
Using the PROBAST prediction-model risk-of-bias tool, researchers classified 56 of 76 studies as high risk of bias. Fourteen were low risk and six were unclear.
The analysis domain caused most of the concern. 53 studies had high risk of bias in that domain, and the most frequent problem was whether there were enough participants with the outcome being predicted.
Small remote-monitoring datasets can produce impressive model scores even when the model has learned dataset quirks rather than a disease pattern that generalizes.
The review’s validation counts point in the same direction:
- 64 studies: Used some form of cross-validation to assess model performance.
- 35 studies: Used k-fold cross-validation.
- 15 studies: Used leave-one-out cross-validation.
- 3 studies: Used external validation, the stronger test of whether a model holds up in a different sample.
Cross-validation is useful, but it is not the same as showing that an algorithm performs well in a new clinic, country, device ecosystem, or patient population.
Reported AI Accuracy Depended on Validation and Feature Choices
The review found many model types. Tree-based methods such as random forests and gradient boosting were the most common, appearing in 19 studies. Random forests alone appeared in 10.
Deep neural networks appeared in 12 studies, including convolutional neural networks and recurrent neural networks. Logistic or linear models, support vector machines, and other classical approaches also appeared.
Model scores varied by reporting metric. AUC was reported in 39 studies, specificity in 38, sensitivity in 37, and accuracy in 31.
The review examined whether study features were tied to performance scores, but prediction horizon, dataset size, disease type, and validation design could confound those comparisons.
Several findings were especially easy to misread:
- Leave-one-out validation: Studies using leave-one-out cross-validation reported higher accuracy, but that does not prove the validation method makes models better.
- Feature engineering: Studies without feature engineering reported higher sensitivity and accuracy, a counterintuitive result likely confounded by methodological differences.
- Downsampling: Downsampling was associated with higher AUC, but class balance and event frequency can change how model metrics behave.
Performance numbers need the full method context. A high accuracy value from a small, internally validated dataset should not be read like a ready clinical tool.
AI Remote Monitoring Models Need External Validation Before Clinical Use
The review also checked whether studies shared code or data. Only 8 studies openly shared algorithm code or anonymized patient data, 18 said code or data could be requested, and 50 studies did not share code or data in the publication.
That limits independent replication. In remote monitoring, replication is not a paperwork issue because device type, sampling frequency, preprocessing, patient adherence, and outcome labeling can all change model behavior.
AI remote monitoring is promising for Parkinson’s disease and other chronic conditions, but the current literature is still method-heavy and validation-light.
Future studies need external validation, interpretable models, clearer reporting, and better attention to privacy and algorithmic fairness. Without those steps, an AI model may look accurate in a paper but fail when patients wear different devices or receive care in different systems.
Citation: DOI: 10.1186/s12911-026-03495-0. Wolber et al. Predicting disease outcomes from remote monitoring using machine learning: a systematic review. BMC Medical Informatics and Decision Making. 2026;26:145.
Study Design: PRISMA-guided systematic review of prospective remote-monitoring machine-learning studies.
Sample Size: 76 included studies selected from 6,668 initially identified records.
Key Statistic: 56 of 76 studies, or 73.7%, were classified as high risk of bias.
Caveat: The review summarized heterogeneous prediction studies and did not show that any one model is ready for clinical deployment.